The Weekly Source Code 35 - Zip Compressing ASP.NET Session and Cache State
Recently while talking to Jeff Atwood and his development team about StackOverflow he mentioned that he compresses the Cache or Session data in ASP.NET which enables him to store about 5-10x more data. They do it with some helper methods but I thought it'd be interesting to try it myself.
There's a lot of options and thoughts and quasi-requirements on how to pull this off:
- I could create my own SessionStateModule, basically replacing the default Session state mechanism completely.
- I could create a number of extension methods to HttpSessionState.
- I could just use helper methods, but that means I have to remember to use them on the in and the out and it doesn't feel like the way I'd use it day to day. However, the benefit to this approach is that it's very VERY simple and I can zip up whatever I want, whenever, and put it wherever.
- I didn't want to accidentally put something in zipped and take it out unzipped. I want to avoid collisions.
- I'm primarily concerned about storing strings (read: angle brackets), rather than binary serialization and compression of objects.
- I want to be able to put zipped stuff in the Session, Application and Cache. I realized that this was the primary requirement. I didn't realize it until I started writing code from the outside. Basically, TDD, using the non-existent library in real websites.
My False Start
I initially thought I wanted it to look and work like this:
Session.ZippedItems["foo"] = someLargeThing;
someLargeThing = Session.ZippedItems["foo"]; //string is implied
But you can't do extension properties (rather than extension methods) or operator overloading.
Then I though I'd do it like this:
public static class ZipSessionExtension
{
public static object GetZipItem(this HttpSessionState s, string key)
{
//go go go
}
}
And have GetThis and SetThat all over...but that didn't feel right either.
How It Should Work
So I ended up with this once I re-though the requirements. I realized I'd want it to work like this:
Session["foo"] = "Session: this is a test of the emergency broadcast system.";
Zip.Session["foo"] = "ZipSession this is a test of the emergency broadcast system.";
string zipsession = Zip.Session["foo"];
Cache["foo"] = "Cache: this is a test of the emergency broadcast system.";
Zip.Cache["foo"] = "ZipCache: this is a test of the emergency broadcast system.";
string zipfoo = Zip.Cache["foo"];
Once I realized how it SHOULD work, I wrote it. There's a few interesting things I used and re-learned.
I initially wanted the properties to be indexed properties and I wanted to be able to type "Zip." and get intellisense. I named the class Zip and made it static. There's two static properties name Session and Cache respectively. They each have an indexer, which makes Zip.Session[""] and Zip.Cache[""] work. I prepended the word "zip" to the front of the key in order to avoid collisions with uncompressed content, and to create the illusion there were two different places.
using System.IO;
using System.IO.Compression;
using System.Diagnostics;
using System.Web;
namespace HanselZip
{
public static class Zip
{
public static readonly ZipSessionInternal Session = new ZipSessionInternal();
public static readonly ZipCacheInternal Cache = new ZipCacheInternal();
public class ZipSessionInternal
{
public string this[string index]
{
get
{
return GZipHelpers.DeCompress(HttpContext.Current.Session["zip" + index] as byte[]);
}
set
{
HttpContext.Current.Session["zip" + index] = GZipHelpers.Compress(value);
}
}
}
public class ZipCacheInternal
{
public string this[string index]
{
get
{
return GZipHelpers.DeCompress(HttpContext.Current.Cache["zip" + index] as byte[]);
}
set
{
HttpContext.Current.Cache["zip" + index] = GZipHelpers.Compress(value);
}
}
}
public static class GZipHelpers
{
public static string DeCompress(byte[] unsquishMe)
{
using (MemoryStream mem = new MemoryStream(unsquishMe))
{
using (GZipStream gz = new GZipStream(mem, CompressionMode.Decompress))
{
var sr = new StreamReader(gz);
return sr.ReadToEnd();
}
}
}
public static byte[] Compress(string squishMe)
{
Trace.WriteLine("GZipHelper: Size In: " + squishMe.Length);
byte[] compressedBuffer = null;
using (MemoryStream stream = new MemoryStream())
{
using (GZipStream zip = new GZipStream(stream, CompressionMode.Compress))
{
using (StreamWriter sw = new StreamWriter(zip))
{
sw.Write(squishMe);
}
//Dont get the MemoryStream data before the GZipStream is closed since it doesn’t yet contain complete compressed data.
//GZipStream writes additional data including footer information when its been disposed
}
compressedBuffer = stream.ToArray();
Trace.WriteLine("GZipHelper: Size Out:" + compressedBuffer.Length);
}
return compressedBuffer;
}
}
}
}
Note that if the strings you put in are shorter than about 300 bytes, they will probably get LARGER. So, you'll probably only want to use these if have strings of more than a half K. More likely you'll use these if you have a few K or more. I figure these would be used for caching large chunks of HTML.
As an aside, I used Trace.WriteLine to show the size in and the size out. Then, in the web.config I added this trace listener to make sure my Trace output from my external assembly showed up in the ASP.NET Tracing:
<system.diagnostics>
<trace>
<listeners>
<add name="WebPageTraceListener"
type="System.Web.WebPageTraceListener, System.Web,
Version=2.0.3600.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a"/>
</listeners>
</trace>
</system.diagnostics>
<system.web>
<trace pageOutput="true" writeToDiagnosticsTrace="true" enabled="true"/>
...
The resulting trace output is:
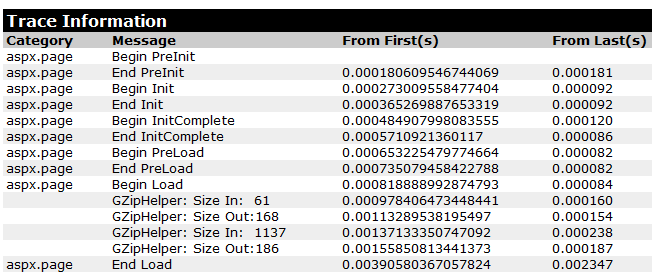
When To Compress
See how the first zipped string got bigger? I shouldn't have put it in there, it was initially too small. The second one went from 1137 bytes to 186, so that was reasonably useful. Again, IMHO, this probably won't matter unless you were storing thousands of strings in cache that were grater than 1k, but as you get towards 10k or more, I suspect you'd get some more value.
For example, if I put 17k of basic HTML in the cache, it squishes it 3756 bytes, a 78% savings. It all depends on how repetitive the markup is and how many visitors you have. If you had a thousand visitors on a machine simultaneously, and you were caching, say, 20 chunks of 100k each, times 1000 users, you'd use about 244 megs for your cache. When I was working in banking, we might have tens of thousands of users online at a time, and we'd be caching historical checking or savings data, and that data might get to 500k or more of XML. Four savings accounts * 70,000 users * 500k of XML history might be 16gigs of RAM (across many servers, so maybe a gig or half-gig per server.) Squishing that 500k to 70k would reduce the hit to 2gigs total. It all depends on how much you're storing, how much it'll compress (how repetitive it is) and how often it's accessed.
Memcached 2 includes a setCompressThreshold that lets you adjust the minimum savings you want before it'll compress. I suspect Velocity will have some similar setting.
Ultimately, however, this all means nothing unless you measure. For example, all this memory savings might be useless if the data is being read and written constantly. You'd be trading any savings from squishing for other potential problems like the memory you need hold the decompressed values as well as memory fragmentation. Point is, DON'T just turn this stuff on without measuring.
Nate Davis had a great comment on the StackOverflow show I wanted to share here:
If they are caching final page output in this way and they are already sending HTTP responses across the wire as gzip,
then gzipping the output cache would make great sense. But only if they are NOT first unzipping when taking the page out of cache and then re-zipping it up again before sending the response.
If they check the 'Accept-Encoding' header to make sure gzip is supported, then they can just send the gzipped output cache directly into the response stream and set the Encoding header with 'gzip'. If Accept-Encoding doesn't include gzip, then the cache would have to be unzipped, but this is a very small percentage of browsers.
Nate is pointing out that one should think about HOW this data will be used. Are you caching and entire page or iFrame? If so, you might be able to send it right back out, still compressed to the browser.
However, if you've got IIS7 and you want to cache a whole page rather than just a per user fragment, consider using IIS7's Dynamic Compression. You've already got this feature, and along with ASP.NET's OutputCaching, the system already knows about gzip compression. It'll store the gzipp'ed version and serve it directly.
My Conclusion?
- I might use something like this if I was storing large string fragments in a memory constrained situation.
- I always turn compression on at the Web Server level. It's solving a different problem, but there's really NO reason for your web server to be serving uncompressed content. It's wasteful not to turn it on.
Thoughts? What is this missing? Useful? Not useful?
About Scott
Scott Hanselman is a former professor, former Chief Architect in finance, now speaker, consultant, father, diabetic, and Microsoft employee. He is a failed stand-up comic, a cornrower, and a book author.
About Newsletter

For me this makes more sense because now I don't have to remember (or for that matter my college's don't have to check) when I compress or not, and you could make it configurable without having to touch any code.
-Mark

I think there is a don't missing :-) But thanks for the article, that looks quite interesting!

StateServer started to falter, so we wrote our own SessionState implementation, using SqlExpress2005 as our backing data store. It works great, and we use the same Session["foo"] = bar; syntax in Asp.Net
There are lots of reporting and analysis options available to us now that we know everything that is going on in people's sessions. We decided to open source this technique and session state provider at: http://codeplex.com/DOTSS It's still very raw, but we're going to add more to it, and would love the community's feedback.
Also, Remoting and MSMQ are suspect in this area as well. We've implemented a compression agent during the serialization and deserialization of objects to optimize network traffic for those technologies as well.

I couldn't go to bed before answering your question :)
I would probably change your code to this:
public class ZipSessionInternal
{
public string this[string index]
{
get
{
return ProcessGetterData(HttpContext.Current.Session[index]);
}
set
{
HttpContext.Current.Session[index] = ProcessSetterData(value);
}
}
private string ProcessSetterData(string data)
{
return ShouldCompress(data) ? "zip_" + GZipHelpers.Compress(data) : data;
}
private bool ShouldCompress(string data)
{
// place what ever logic here you want, maybe just reading from a configuration setting
// or make it smart, the heavier the load (more memory consumption) the more you want to
// compress
return (data.Length > 500);
}
private string ProcessGetterData(string data)
{
return data.StartsWith("zip_") ? GZipHelpers.DeCompress(data.Substring(4, data.Length) as byte[]) : data;
}
public AddUnCompressed(string index, string data)
{
HttpContext.Current.Session[index] = data;
}
}
I didn't add the zip keyword before to none compressed data (as I said in my previous comment) but I added it to the compressed data, doesn't matter either way just feels better here. Also I like to note that this is not tested or anything, but it brings across what I meant.
I also added the method AddUnCompressed for when you know that a value is going to be retrieved a lot and you don't want the overhead of uncompressing it. So effectively by passing the compression rules.
Let me know what you think of this and why you didn't go for something like this, I especially like it that you can tell your developers, hey always use the static zip class to store and retrieve your session data.
-Mark
How about putting it up on CodePlex and managing it? You've got contributors right on this thread.
To be a winner, it would need to be completely transparent at the application level -- which is clearly your goal above. This would make it a "freebie" just like IIS compression -- use it or don't, no app changes necessary.
If you want to go further, add configurability on the threshold as Mark does. Give it a reasonable default and give it a section in web.config.

Note that if the strings you put in are shorter than about 300 bytes, they will probably get LARGER. So, you'll probably only want to use these if have strings of more than a half K.
Hey cool! Awesome entry -- glad you had time to follow up on this!
I agree that the breakeven point for this is at around 300 bytes; if passed a string shorter than 256 bytes we just (silently) store it normally and skip the compression/decompression.

public static class Zip
{
public static readonly ZipInternal Session = new ZipInternal(s => HttpContext.Current.Session[s] as byte[], (s, b) => HttpContext.Current.Session[s] = b);
public static readonly ZipInternal Cache = new ZipInternal(s => HttpContext.Current.Cache[s] as byte[], (s, b) => HttpContext.Current.Cache[s] = b);
public class ZipInternal
{
readonly Func<string, byte[]> _get;
readonly Action<string, byte[]> _set;
public ZipInternal(Func<string, byte[]> get, Action<string, byte[]> set)
{
_get = get;
_set = set;
}
public string this[string index]
{
get
{
return Zip.GZipHelpers.DeCompress(_get("zip" + index));
}
set
{
_set("zip" + index, Zip.GZipHelpers.Compress(value));
}
}
}
}

Compress that BinaryStream after the fact and before it is pushed into the State Store.
Seriously, take a look at http://codeplex.com/dotss I've got this problem already started being fixed. Check my blog for the blog post that lead into my investigation of the state compression issue: http://csharponthefritz.spaces.live.com

Your project look interesting too, but requires a SQL instance, this is almost never an issue I know. And I am sure you can appreciate different views on the same problem?
-Mark
I think zipping the session is great, but I can't go with the Session["foo"] = syntax.
You get more benefit by having a wrapper for the session to enforce strong typing (http://www.tigraine.at/2008/07/17/session-handling-in-aspnet/), and that wrapper can then do the compression transparently.
Having the business logic think about zipping isn't really beneficial (rather couples those too even further).
-Daniel

Thanks for mentioning my comments from the StackOverflow show.
I decided to try out sending GZipped Output Cache directly to the browser. I came up with the following for Web Forms pages. It is a base page class that uses and HttpResponse.Filter to Zip up the stream depending upon the 'Accept-Encoding' request header:
[code]
using System;
using System.Web;
using System.IO.Compression;
public class MyBasePage : System.Web.UI.Page
{
protected bool UseCompression = true;
protected override void OnInit(EventArgs e)
{
if (UseCompression) { SetupCompressedStream(); }
base.OnInit(e);
}
private void SetupCompressedStream()
{
HttpResponse response = HttpContext.Current.Response;
string acceptEncodingValue = HttpContext.Current.Request.Headers["Accept-Encoding"];
if (acceptEncodingValue.Contains("gzip"))
{
response.Filter = new GZipStream(response.Filter, CompressionMode.Compress);
response.AppendHeader("Content-Encoding", "gzip");
}
else if (acceptEncodingValue.Contains("deflate"))
{
response.Filter = new DeflateStream(response.Filter, CompressionMode.Compress);
response.Headers["Content-Encoding"] = "deflate";
}
}
}
[code]
Then in the actual aspx page:
[code]
<%@ OutputCache Duration="10" VaryByHeader="Accept-Encoding" VaryByParam="*" %>
[code]
The only problem with this is that if the developer forgets the VaryByHeader="Accept-Encoding" in the page OutputCache directive. It will cause problems. But altogether this should work pretty well and do the following:
- Smaller HTTP response going across the wire
- More Output Cache can fit into memory
This logic could also be easily put into a IResultFilter in an MVC app as well.
Thanks,
Nate Davis

http://blog.madskristensen.dk/post/Compression-and-performance-GZip-vs-Deflate.aspx



Could this be used to say store large recordsets? Say you load up a list of user objects, a list of address objects, and a list of car objects. Could you just serialize these lists to xml, compress them, then use in a page with three tabs that each tab contains a datagrid? This would stop the need to go back to the database every time you load the grid and I would think would be a lot more memory efficient than say keeping all three lists in memory uncompressed.
Maybe if you are caching lists of objects that don't need to be refreshed often like a list of countries?
Again, not the best example I'm sure, but the main idea is to keep large amounts of recordset like data in memory. Hope I didn't completely miss the point here.

In other words, if your code looks like this:
MyClass myObject = new MyClass();
myObject.MyProperty = "foo";
Session["SessionVar"] = myObject;
MyClass retrievedObject1 = (MyClass) Session["SessionVar"];
retrievedObject1.MyProperty = "bar";
MyClass retrievedObject2 = (MyClass) Session["SessionVar"];
Then retrievedObject2's Property1 property would still be "foo" instead of "bar". The only solution I can think of that would enable you to use the object stored in session and have changes to it persist to the Session would be to tap into an event exposed by the ASP.NET framework that handled the serializing / deserializing of the Session data.

The zipped data tends to involves fewer network traffic when accessing cache servers. It will make time spend on sending/receiving cache data from cache servers shorter, at the expense of CPU time for zip/unzip.
So, it seems to be a completition of network transmission and zip/unzip in memory, and it looks the latter probably wins...

e.g. var bang = Zip.Session["bang!"];
We therefore either need a guard clause to inspect for null input in the DeCompress Method and return null. Or if we prefer exception behaviour for incorrect input parameters we would instead change the zip internal to return null if there is no Cache/Session entry.
I really liked Aaron's DRY version of the ZipInternal, so his setter would become:
public string this[string index]
{
get
{
var entry = _get("zip" + index);
if(entry==null)
return null;
return Zip.GZipHelpers.DeCompress(entry);
}
set
{
_set("zip" + index, Zip.GZipHelpers.Compress(value));
}
}

Very good article!
I made my custom implementation about that using Generic Class and BinaryFormatter in order to manage any type of objets to store into Cache and Session.
You can check it out here : http://blog.sb2.fr/post/2008/11/18/Compression-ASPNET-Session-et-Cache.aspx
It's in french (sorry i'm french :) but any comments in english are welcome too !
I will be pretty happy to get feedbacks about my implementation.
Thanks !

Now image what you could do with this wrapper (or adapter if you will)... Custom tracing, logging, encrypting/decrypting, compression, etc, without having to change a single line of code of the application.
Just another ideia to the pile :)
Keep up the good work

Comments are closed.
One possible optimization - if the compressed string is larger than the uncompressed one, just store it uncompressed, with a flag that indicates that. Then you don't take more memory than necessary, and avoid the uncompression cost when reading it out.